 搜索引摩工作过程非常复 ,接下来的几节我们简单介绍搜索引案是怎样实现网面排名的。这里介绍的内容相对于真正的搜索引擎技术来说只是皮毛,不过对SEO人员已经
搜索引摩工作过程非常复 ,接下来的几节我们简单介绍搜索引案是怎样实现网面排名的。这里介绍的内容相对于真正的搜索引擎技术来说只是皮毛,不过对SEO人员已经
足够用了。
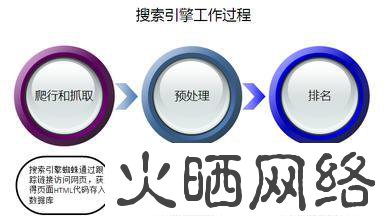
搜索引擎的工作过程大体上可以分成三个阶段。
(1)爬行和抓取:搜索引紧蜘蛛通过跟踪链接访问网页,获得页面HTML代码存入数据库。
(2)预处理:索引程序对抓取来的页面数据进行文字提取、中文分词、索引等处理,以备排名程序调用。
(3)排名:用户输入关键词后,排名程序调用索引库数据,计算相关性,然后按一定格式生成搜索结果页面。
爬行和抓取
爬行和抓取是搜索引擎工作的第一步,完成数据收集的任务。
1.蜘蛛
搜索引擎用来爬行和访问页面的程序被称为蜘蛛(spider),也称为机器人(bot)。搜索引擎蜘蛛访问网站页面时类似于普通用户使用的浏览器。蜘蛛程序发出页面访问请求后,服务器返回HTML代码,蜘蛛程序把收到的代码存入原始页面数据库。搜索引擎为了提高爬行和抓取速度,都使用多个蜘蛛并发分布爬行。蜘蛛访问任何一个网站时,都会先访问网站根目录下的robots.txt文件。如果robots.xt
文件禁止搜索引擎抓取某些文件或目录,蜘蛛将遵守协议,不抓取被禁止的网址。和浏览器一样,搜索引擎蜘蛛也有标明自己身份的代理名称,站长可以在日志文件中看到搜索引擎的特定代理名称,从而辨识搜索引擎蜘蛛。下面列出常见的搜索引案蜘蛛名称:
·Baiduspidert+(+ http://www.baidu.com/search/spider.htm)百度蜘蛛
http://www.baidu.com/search/spider.htm)百度蜘蛛
·Mozilla/5.0(compatible;Yahoo!Slurp China;htp:/misc.yahoo.com.cn/help.htm)雅虎中国蜘蛛
·Mozilla/5.0(compatible;Yalhool Slurp/3.0;htp:/help.yahoo.com/helpus/ysearchyslup)英文雅虎蜘蛛
·Morilla/s,0(compaible;Googletbot2.1;thtp/www gogle.conm/bothtm) Gogle 蜘蛛
·msnbot/1.1(+http:/search.msn.com/msnbot.htm)微软Bing蜘妹
·Sogou+webtrobott(htp:/wwwsogou.com/docs/help/webmastershtmHO7)搜狗蜘炼
·Sosospider+(+http:/help.soso.com/webspider.htm)搜搜蜘蛛
·Mozilla/5.0(compatible;YodaoBo/1.0;htp:/wwwyodao.com/helpywebmaster/spider:)有道蜘妹
2.跟踪链接
为了抓取网上尽量多的页面,搜索引擎蜘蛛会跟踪页面上的链接,从一个页面爬到下一个页面,就好像蜘蛛在蜘蛛网上爬行那样,这也就是搜索引擎蜘蛛这个名称的由来。
整个互联网是由相互链接的网站及页面组成的。从理论上说,蜘蛛从任何一个页面出发,顺着链接都可以爬行到网上的所有页面。当然,由于网站及页面链接结构异常复杂,蜘蛛需要采取一定的爬行策略才能遍历网上所有页面。最简单的爬行遍历策略分为两种,一种是深度优先,另一种是广度优先。所谓深度优先,指的是蜘蛛沿着发现的链接一直向前爬行,直到前面再也没有其他链
接,然后返回到第一个页面,沿着另一个链接再一直往前爬行。蜘蛛跟踪链接,从A页面爬行到A1,A2,A3,A4,到A4页面后,已经没有其他链接可以跟踪就返回A页面,顺着页面上的另一个链接,爬行到B1,B2,
B3,B4。在深度优先策略中,蜘蛛一直爬到无法再向前,才返回爬另一条线。广度优先是指蜘蛛在一个页面上发现多个链接时,不是顺着一个链接一直向前,而是把
页面上所有第一层链接都爬一遍,然后再沿着第二层页面上发现的链接爬向第三层页面。蜘蛛从A页面顺着链接爬行到A1,B1,C1页面,直到A页面上的所
有链接都爬行完,然后再从A1页面发现的下一层链接,爬行到A2,A3,A4,……页面。,都能爬完整个从理论上说,无论是深度优先还是广度优先,只要给蜘蛛足够的时间,配展一高面。互联微。“是委语,在鲜牛谢紧的命这资部、时物都不是无限的,也不可小部分。实际上最大的提索引掌也只是展行和收录了互联师的一一部贫点到尽量多的网站《广度化深股我关第产股优先通常是混合使用的,这样既先),也能照顾到一部分网站的内页(深度优先)。

 网站制作费用:0898-66830524 /微信:17776819008
网站制作费用:0898-66830524 /微信:17776819008







 2368323272
2368323272 17776819008
17776819008 0898-66830524
0898-66830524